
[알고리즘] 정렬 알고리즘 정리
버블 정렬
두 인접한 데이터를 비교해서, 앞에 있는 데이터가 뒤에 있는 데이터보다 크면, 자리를 바꾸는 정렬 알고리즘

# 버블 정렬
def bubble_sort(array):
for n in range(len(array)):
for i in range(len(array) - n - 1):
if array[i] > array[i+1]:
array[i], array[i+1] = array[i+1], array[i]
return array
삽입 정렬
- 삽입 정렬은 두 번째 인덱스부터 시작
- 해당 인덱스(key 값) 앞에 있는 데이터(B)부터 비교해서 key 값이 더 작으면, B값을 뒤 인덱스로 복사
- 이를 key 값이 더 큰 데이터를 만날때까지 반복, 그리고 큰 데이터를 만난 위치 바로 뒤에 key 값을 이동

def insertion_sort(array):
for n in range(len(array)): # array 크기만큼 반복
data = array[n] # n번째 데이터
for i in range(n, 0, -1):
if data < array[i - 1]: # n번째 데이터와 그 이전 데이터들을 차례로 비교
array[i - 1], array[i] = array[i], array[i - 1]
else:
break
return array
선택 정렬
- 다음과 같은 순서를 반복하며 정렬하는 알고리즘
- 주어진 데이터 중, 최소값을 찾음
- 해당 최소값을 데이터 맨 앞에 위치한 값과 교체함
- 맨 앞의 위치를 뺀 나머지 데이터를 동일한 방법으로 반복함
def selection_sort(array):
for i in range(len(array) - 1):
for j in range(i, len(array)):
min = array[i]
if min > array[j]:
array[i], array[j] = array[j], array[i]
min = array[j]
return array
퀵 정렬
- 정렬 알고리즘의 꽃
- 기준점(pivot 이라고 부름)을 정해서, 기준점보다 작은 데이터는 왼쪽(left), 큰 데이터는 오른쪽(right) 으로 모으는 함수를 작성함
- 각 왼쪽(left), 오른쪽(right)은 재귀용법을 사용해서 다시 동일 함수를 호출하여 위 작업을 반복함
- 함수는 왼쪽(left) + 기준점(pivot) + 오른쪽(right) 을 리턴함
import random
def QuickSort(array):
if len(array) < 2: # 재귀함수 사용을 위한 base case를 지정
return array
pivot = array[0]
less = [i for i in array[1:] if i <= pivot]
bigger = [i for i in array[1:] if i > pivot]
array = QuickSort(less) + [pivot] + QuickSort(bigger)
return array
합병 정렬
정렬 알고리즘 방법 중 하나로,
분할 정복 알고리즘을 이용한다.
# 분할정복 (divide and conquer)
문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다.
합병 정렬은 하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음,
두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다. 합병 정렬은 다음의 단계들로 이루어진다.
- 분할(Divide): 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다.
- 정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용하여 다시 분할 정복 방법을 적용한다.
- 결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.

''' divide and conquer 방법으로 부분적으로 나누어 생각한다.
먼저 정렬된 두 리스트를 정렬된 채로 합치는 함수 '''
def merge(list1, list2):
i = 0
j = 0
# 정렬된 항목들을 담을 리스트
merged_list = []
# list1과 list2를 돌면서 merged_list에 항목 정렬
while i < len(list1) and j < len(list2):
if list1[i] > list2[j]:
merged_list.append(list2[j])
j += 1
else:
merged_list.append(list1[i])
i += 1
# list2에 남은 항목이 있으면 정렬 리스트에 추가
if i == len(list1):
merged_list += list2[j:]
# list1에 남은 항목이 있으면 정렬 리스트에 추가
elif j == len(list2):
merged_list += list1[i:]
return merged_list
# 합병 정렬
def merge_sort(my_list):
if len(my_list) < 2:
return my_list
list1 = my_list[:len(my_list)//2]
list2 = my_list[len(my_list)//2:]
return merge(merge_sort(list1), merge_sort(list2))
힙 정렬
힙이란?
데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree)
힙은 완전 이진트리이고, 자식 노드들이 특정한 성질을 가지고 정렬되어 있는 구조이다.
부모 노드가 자식 노드들보다 크다면 최대 힙(Max Heap)구조라고 하고, 부모 노드가 자식 노드들보다 작다면 최소 힙(Min Heap)구조라고 한다.
힙의 조건
- 각 노드의 값은 해당 노드의 자식 노드가 가진 값보다 크거나 같다. (최대 힙의 경우)
- 최소 힙의 경우는 각 노드의 값은 해당 노드의 자식 노드가 가진 값보다 크거나 작음
- 완전 이진 트리 형태를 가짐
힙 정렬 구현
def heapify(tree, index, tree_size): # 주어진 배열(tree)에서
"""배열의 해당 인덱스를 heap으로 만드는 함수"""
# 왼쪽 자식 노드의 인덱스와 오른쪽 자식 노드의 인덱스
left_child_index = 2 * index
right_child_index = 2 * index + 1
largest = index # 일단 부모 노드의 값이 가장 크다고 설정
# 왼쪽 자식 노드의 값과 비교
if 0 < left_child_index < tree_size and tree[largest] < tree[left_child_index]:
largest = left_child_index
# 오른쪽 자식 노드의 값과 비교
if 0 < right_child_index < tree_size and tree[largest] < tree[right_child_index]:
largest = right_child_index
if largest != index: # 부모 노드의 값이 자식 노드의 값보다 작으면
tree[index], tree[largest] = tree[largest], tree[index] # 부모 노드와 최댓값을 가진 자식 노드의 위치를 바꿔준다
heapify(tree, largest, tree_size) # 자리가 바뀌어 자식 노드가 된 기존의 부모 노드를 대상으로 heap 과정을 거친다
- 해당 heapify 동작을 마지막 노드부터 루트 노드까지 수행하면 전체 트리가 힙 조건을 만족한다.
def heapsort(tree):
"""힙 정렬 함수"""
tree_size = len(tree)
# 마지막 인덱스부터 처음 인덱스까지 heapify를 호출한다 -> 받은 리스트 (tree)를 힙으로 만듦
for index in range(tree_size, 0, -1):
heapify(tree, index, tree_size) -> tree는 힙이 된다.
# 마지막 인덱스부터 처음 인덱스까지
for i in range(tree_size-1, 0, -1):
tree[1], tree[i] = tree[i], tree[1]
heapify(tree, 1, i)
'''가장 큰 수인 루트노드 tree[1]과 마지막 노드를 교환 하면
마지막 노드가 가장 큰 수가 됌.
그 다음 마지막 인덱스를 제외한 나머지 리스트로 같은 과정을 반복하면
높은 숫자부터 쌓여 오름차순으로 정렬되게 된다.'''
계수 정렬(Counting Sort)
계수 정렬이라고 부른다.- 항목들의 순서를 결정하기 위해 집합에 각 항목이 몇 개씩 있는지 세는 작업을 하여 선형 시간에 정렬하는 알고리즘
- data에서 각 항목들의 발생 횟수를 세고, 정수 항목들로 직접 인덱스 되는 카운트 배열
count에 저장한다.
카운팅 정렬 과정
counting배열에, 주어진data의 각 요소 출현 횟수를 담는다.counting배열에서 누적 counting을 구한다.data의 요소 값을 뒤에서부터 가져와 counting의 값으로 index를 찾고 새로운 빈 배열result에 값을 요소 값을 넣는다. 이 때 누적 counting 값에서 -1을 해준다.
def counting_sort(data, count, result):
for i in data:
count[i] += 1 # data 요소의 출현 횟수
print("count", count)
for i in range(len(count)-1):
count[i+1] += count[i] # 누적 count
print("누적 count", count)
for i in range(len(data)-1, -1, -1):
result[count[data[i]] - 1] = data[i]
count[data[i]] -= 1
print("result", result, "count", count)
data = [3, 2, 5, 4, 2, 1, 5, 2, 2, 1]
count = [0 for _ in range(max(data)+1)] # 최댓값
result = [0 for _ in range(len(data))] # data 길이만큼
counting_sort(data, count, result)
print(result)
--------------------------------------------------------------
>>> count [0, 2, 4, 1, 1, 2]
>>> 누적 count [0, 2, 6, 7, 8, 10]
>>> result [0, 1, 0, 0, 0, 0, 0, 0, 0, 0] count [0, 1, 6, 7, 8, 10]
>>> result [0, 1, 0, 0, 0, 2, 0, 0, 0, 0] count [0, 1, 5, 7, 8, 10]
>>> result [0, 1, 0, 0, 2, 2, 0, 0, 0, 0] count [0, 1, 4, 7, 8, 10]
>>> result [0, 1, 0, 0, 2, 2, 0, 0, 0, 5] count [0, 1, 4, 7, 8, 9]
>>> result [1, 1, 0, 0, 2, 2, 0, 0, 0, 5] count [0, 0, 4, 7, 8, 9]
>>> result [1, 1, 0, 2, 2, 2, 0, 0, 0, 5] count [0, 0, 3, 7, 8, 9]
>>> result [1, 1, 0, 2, 2, 2, 0, 4, 0, 5] count [0, 0, 3, 7, 7, 9]
>>> result [1, 1, 0, 2, 2, 2, 0, 4, 5, 5] count [0, 0, 3, 7, 7, 8]
>>> result [1, 1, 2, 2, 2, 2, 0, 4, 5, 5] count [0, 0, 2, 7, 7, 8]
>>> result [1, 1, 2, 2, 2, 2, 3, 4, 5, 5] count [0, 0, 2, 6, 7, 8]
>>> [1, 1, 2, 2, 2, 2, 3, 4, 5, 5]
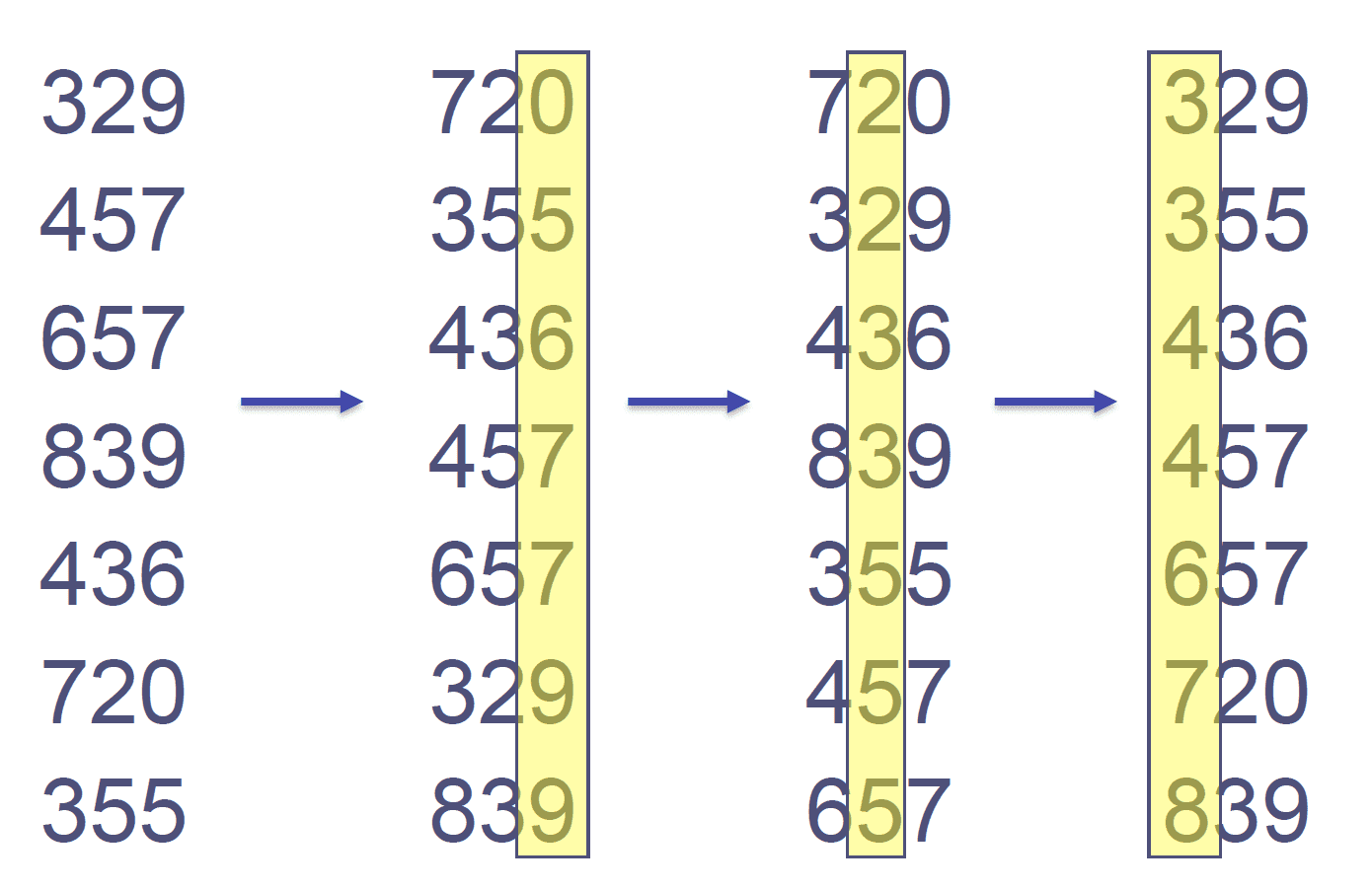
기수 정렬(Radix Sort)
-
Radix sort(기수정렬)의 기본 아이디어는 각각 자리수끼리 비교해서 정렬을 하는 것이다. 자릿수를 비교할 때는
counting sort를 사용 한다. Radix sort에 대해 찾아보면 LSD와 MSD가 있다는 것을 알 수 있다. LSD는 가장 낮은 자릿수부터 비교하면서 정렬을 하는 것이고, MSD는 가장 높은 자릿수부터 비교하면서 정렬을 하는 것이다. 자릿수가 고정되어있기 때문에stable한 알고리즘이다. -
Radix Sort는
O(kn)의 시간복잡도를 가지고 있는 정렬 알고리즘이다 (k는 가장 큰 데이터의 자릿수이다). 이 알고리즘이 작동하려면 몇가지의 조건들이 필요하다:
- 숫자이어야 한다 (ex. [“banana”, “apple”] 와 같은 리스트는 정렬 불가)
- 정수여야 한다 (ex. [12.332, 29.112] 와 같은 리스트는 정렬 불가)
위의 조건들을 만족하지 않으면 Radix sort는 사용할 수 없다. 그리고 자릿수(k)의 크기가 클 수록 알고리즘의 속도도 늘어나기 때문에 k가 작은 상황일수록 더 빠르게 정렬을 할 수 있다.
def countingSort(arr, digit):
n = len(arr)
# 배열의 크기에 맞는 output 배열을 생성하고 10개의 0을 가진 count란 배열을 생성한다.
output = [0] * (n)
count = [0] * (10)
#digit, 자릿수에 맞는 count에 += 1을 한다.
for i in range(0, n):
index = int(arr[i]/digit)
count[ (index)%10 ] += 1
# count 배열을 수정해 digit으로 잡은 포지션을 설정한다.
for i in range(1,10):
count[i] += count[i-1]
print(i, count[i])
# 결과 배열, output을 설정한다. 설정된 count 배열에 맞는 부분에 arr원소를 담는다.
i = n - 1
while i >= 0:
index = int(arr[i]/digit)
output[ count[ (index)%10 ] - 1] = arr[i]
count[ (index)%10 ] -= 1
i -= 1
#arr를 결과물에 다시 재할당한다.
for i in range(0,len(arr)):
arr[i] = output[i]
# Method to do Radix Sort
def radixSort(arr):
# arr 배열중에서 maxValue를 잡아서 어느 digit, 자릿수까지 반복하면 될지를 정한다.
maxValue = max(arr)
#자릿수마다 countingSorting을 시작한다.
digit = 1
while int(maxValue/digit) > 0:
countingSort(arr,digit)
digit *= 10
arr = [ 170, 45, 75, 90, 802, 24, 2, 66]
#arr = [4, 2, 1, 5, 7, 2]
radixSort(arr)
for i in range(len(arr)):
print(arr[i], end=" ")
정렬 알고리즘 비교

시간복잡도 비교

Sorting Algorithms Animations
# 다양한 정렬 알고리즘 비교 사이트
List Operations
| Operation | Code | Average Case |
|---|---|---|
| 인덱싱 | my_list[index] |
O(1) |
| 정렬 | my_list.sort() sorted(my_list) |
O(nlgn) |
| 뒤집기 | my_list.reverse() |
O(n) |
| 탐색 | element in my_list |
O(n) |
| 끝에 요소 추가 | my_list.append(element) |
O(1) |
| 중간에 요소 추가 | my_list.insert(index, element) |
O(n) |
| 삭제 | del my_list[index] |
O(n) |
| 최솟값, 최댓값 찾기 | min(my_list) max(my_list) |
O(n) |
| 길이 구하기 | len(my_list) |
O(1) |
| 슬라이싱 | my_list[a:b] |
O(b−a) |
Dictionary Operations
| Operation | Code | Average Case |
|---|---|---|
| 값 찾기 | my_dict[key] |
O(1) |
| 값 넣어주기/덮어쓰기 | my_dict[key] = value |
O(1) |
| 값 삭제 | del my_list[key] |
O(1) |
댓글남기기