
[DB] DataBase 개념 정리
1. 데이터 베이스 ACID원칙
- 원자성(Atomicity) : 트랜잭션 과정들이 전부 반영되거나 아예 반영되지 않는 것
- 일관성(Consistency) : 트랜잭션이 성공적으로 완료되면 일관적인 DB상태를 유지하는 것
- 격리성(Isolation) : 트랜잭션 수행 시 다른 트랜잭션이 끼어들지 못하도록 보장하는 것
- 지속성(Durability) : 성공적으로 수행된 트랜잭션은 영원히 반영되는 것(Commit 후 영원히 보장)
- ACID 보장
원자성 보장 : 이전 상태를 임시영역(rollback segment)에 저장하고 있음. 확실한 부분에 대해서는 rollback이 되지 않도록 중간 저장 지점인 save point를 지정함.
- 일관성 보장
만약 A_id 의 제약조건이 A 테이블에서 변경되면, A_id를 참조하고 있는 B 테이블에서도 변경되어야 한다.
이러한 일관성 조건은 어떤 이벤트와 조건이 발생했을 때, 트리거(Trigger)를 통해 보장한다.
트리거는 데이터베이스 시스템이 자동적으로 수행할 동작을 명시하는데 사용된다. 트리거가 호출되면 트리거로 작성된 수행할 질의들이 실행된다.
- 고립성 보장
OS의 세마포어(semaphore)와 비슷한 개념으로 lock & excute unlock을 통해 고립성을 보장할 수 있다.
데이터를 읽거나 쓸 때는 문을 잠궈서 다른 트랜잭션이 접근하지 못하도록 고립성을 보장하고, 수행을 마치면 unlock을 통해 데이터를 다른 트랜잭션이 접근할 수 있도록 허용하는 방식
트랜잭션에서는 데이터를 읽을 때, 여러 트랜잭션이 읽을 수는 있도록 허용하는 shared_lock 즉, 데이터 쓰기를 허용하지 않고 오직 읽기만 허용한다.
또한 데이터를 쓸 때는 다른 트랜잭션이 읽을 수도 쓸 수도 없도록 하는 exclusive_lock을 사용한다. 읽기, 쓰기 작업이 끝나면 unlock을 통해 잠금을 해제
그러나 잘못 사용하면 데드락(deadlock)상태에 빠질 수 있다.
2PL 프로토콜(2 Phase Locking protocol)
*2PL 프로토콜이란 여러 트랜잭션이 공유하고 있는 데이터에 동시에 접근할 수 없도록 하기위한 목적을 가진 프로토콜
growing phase : read_lock , write_lock을 의미
shrinking phase : unlock를 의미
즉, 하나의 트랜젝션 안에서는 lock과 unlock이 번갈아 수행되지 않고 lock이 쭉 수행된 후에 unlock이 쭉 수행되어야 한다
-
보수적 locking ( conservative locking )
-
- 트랜잭션이 시작되면 모든 lock을 얻는 방식으로서, 데드락이 발생하지 않지만 병행성이 좋지 못함
-
엄격한 locking ( strict locking )
-
- 트랜잭션이 commit을 만날 때까지 lock을 갖고 있다가 commit을 만날때 unlock을 하는 방식으로 데드락이 발생하지만 병행성이 좋음
- 일반적으로 병행성이 좋은 strict 방식을 사용
2. 정규화 (Normalization)
릴레이션 내에서 중복을 제거하는 과정
용어 정리
-
슈퍼키
-
- 릴레이션에서 특정 튜플을 유일하게 구분할 수 있는 애트리뷰트의 조합을 가진 키
- 튜플을 유일하게 구분할 수 있으면 되기 때문에, 슈퍼키는 여러개 존재할 수 있다.
- 예를 들어, A, B, C 애트리뷰트가 있을 때 (A,B), (B,C) 조합만으로 튜플을 구분 할 수 있다면, 해당 조합이 슈퍼키가 된다.
-
후보키
-
- 슈퍼키 중에서 최소한의 애트리뷰트 조합으로 특정 튜플을 유일하게 구분 할 수 있는 키
-
-
예를 들어, (A,B), (B,C) 슈퍼키가 존재할 때 B 애트리뷰트만으로도 튜플을 구분할 수 있다면, B는후보키
-
- 즉, 슈퍼키보다 작은 범위라고 할 수 있다.
-
-
진부분집합
-
- 진부분집합은 자신을 제외한 부분집합을 의미
- 예를 들어, {1,2} 집합의 부분집합은 {공집합, {1}, {2}, {1,2}}이며, 진부분집합은 {공집합}, {1}, {2}
-
무손실 분해 ( Lossless Decomposition )
-
- 정규화를 진행하는 과정에서 중복을 제거하는 방법으로 릴레이션을 분해합니다. 이 때 원래의 정보를 잃어버리지 않으면서 분해하는 것을 무손실 분해라고 한다.
-
- 즉, 릴레이션을 분해할 때 무손실 분해가 되어야 한다.
- 무손실 분해가 되면 분해된 릴레이션을 join 해서 원래의 정보를 얻을 수 있다.
-
함수 종속성 ( Function Dependency )
-
- 함수 종속성이란, 어떤 릴레이션 R의 애트리뷰트 A, B가 있다고 가정할 때, A의 값을 알면 B의 값을 알 수 있는 관계를 말한다.
- 이 때 A의 값은 유일해야 하며, B는 중복되도 상관이 없다.
- 즉, 키의 값을 알면 다른 임의의 애트리뷰트 값을 구할 수 있는 것처럼, 키의 성질을 정의한 것이라 할 수 있다.
-
결합 종속성 ( Join Dependency )
-
- 결합 종속성이란, 어떤 릴레이션이 여러 개의 릴레이션으로 무손실 분해될 수 있다면, 즉 여러 개의 릴레이션의 결합으로 원래 릴레이션을 만들 수 있는 관계를 말한다.
-
직교성 ( Orthogonality )
-
- 직교성은 여러 개의 릴레이션 사이의 중복제거에 대한 개념이다.
- 정규화는 한 개의 릴레이션의 내부에서 중복을 없애는데 초점을 맞춘 작업인 반면, 직교성은 DB 전체에서 중복을 제거하는 작업이다.
- 제1 정규형, 1NF
릴레이션을 테이블과 같은 형태로 만들어 주는 과정
- 테이블에는 컬럼이나 행에 순서가 존재하지만, 릴레이션에는 순서가 존재하기 않기 때문에 순서를 고려하지 않는다.
- 중복되는 튜플이 존재하지 않음
- 구체적인 값을 가져야 합니다. 즉 값으로 NULL을 갖지 않는다.
- 값은 의미가 있는 한 묶음의 데이터, 즉 원자 단위여야 한다. ( 원자성 )
- 제2 정규형, 2NF
후보키의 진부분집합에서 키가 아닌 속성에 대해, 부분 함수 종속성을 제거하는 작업

함수 종속을 제거하려면 원래의 릴레이션을 무손실 분해시켜야 한다.
-
종속 관계가 있는 속성만 추출해서( projection, 프로젝션 )해서 새로운 릴레이션을 만든다.
-
- 즉 이름과 학년을 애트리뷰트로 갖는 새로운 릴레이션이 생성된다.
- 기존에 있던 원래 릴레이션은 떨어져나간 애트리뷰트( 학년 )를 제외한 릴레이션으로 존재한다.
- 제3정규형, 3NF
3NF는 추이 함수 종속성( Transitive Dependency )을 제거하는 작업
추이 함수 종속성은 키가 아닌 애트리뷰트 사이의 함수 종속성을 의미한다. 예를 들어, 키가 아닌 애트리뷰트 X, Y가 있고, X를 알면 Y값을 알 수 있는 함수 종속성이 있다고 가정했을 때,
3NF는 X와 Y 사이의 함수 종속성을 제거 하는 과정이다..
2NF는 후보키와 키가 아닌 애트리뷰트 사이의 함수 종속성을 제거했다는 점에서 차이가 있다.
3. 인덱스 (Index)
키 값으로 행 데이터의 위치를 식별하는데 사용하는 기능
그러기 위해서는 원본 테이블을 기준으로 잘 정렬된 별도의 테이블, 즉 인덱스 테이블을 생성해야 하고, 이로 인해 데이터 엑세스 성능을 높일 수 있다.
인덱스의 존재 유무에 따라 쿼리의 결과는 달라지지 않는다.
인덱스를 효과적으로 사용하려면 정규화가 되어 있어야 한다.
인덱스 테이블
-
이진트리 검색을 위해서는 미리 데이터가 정렬되어 있어야 한다.
-
데이터가 항상 정렬되어 있기란 어렵기 때문에, 특정 컬럼을 기준으로 이진트리를 생성하는 새로운 테이블을 생성하여 미리 정렬된 상태를 만들어야 한다.
-
MySQL에서는 테이블을 생성할 때 특정 컬럼을 PK로 설정하면, 그 컬럼에 대한 인덱스 테이블을 자동으로 생성
-
인덱스 테이블은 일반 테이블과 같이 데이터베이스 객체이며, 인덱스 테이블만으로는 아무런 기능을 할 수 없기 때문에 다른 테이블에 의존적이다.
-
인덱스 테이블의 단점
- 인덱스 테이블이라는 테이블이 생성되므로 메모리를 많이 소비
- SELECT를 제외한 INSERT, UPDATE, DELETE에 대한 성능 저하 (데이터를 정렬해야 하므로 전체적인 성능이 저하)
인덱스 종류
-
해시 인덱스 ( Hash Index )
-
- 해시 테이블을 이용한 인덱스로, 해시값을 사용
- 해시 값을 사용하기 때문에 매우 빠르지만, 등가비교검색( 값이 같은지 다른지 )만 가능.
- 기본키는 등가비교만 해도 충분한 경우가 많으므로, 해시 인덱스를 고려 가능
- B+ 트리 (Balanced Tree)
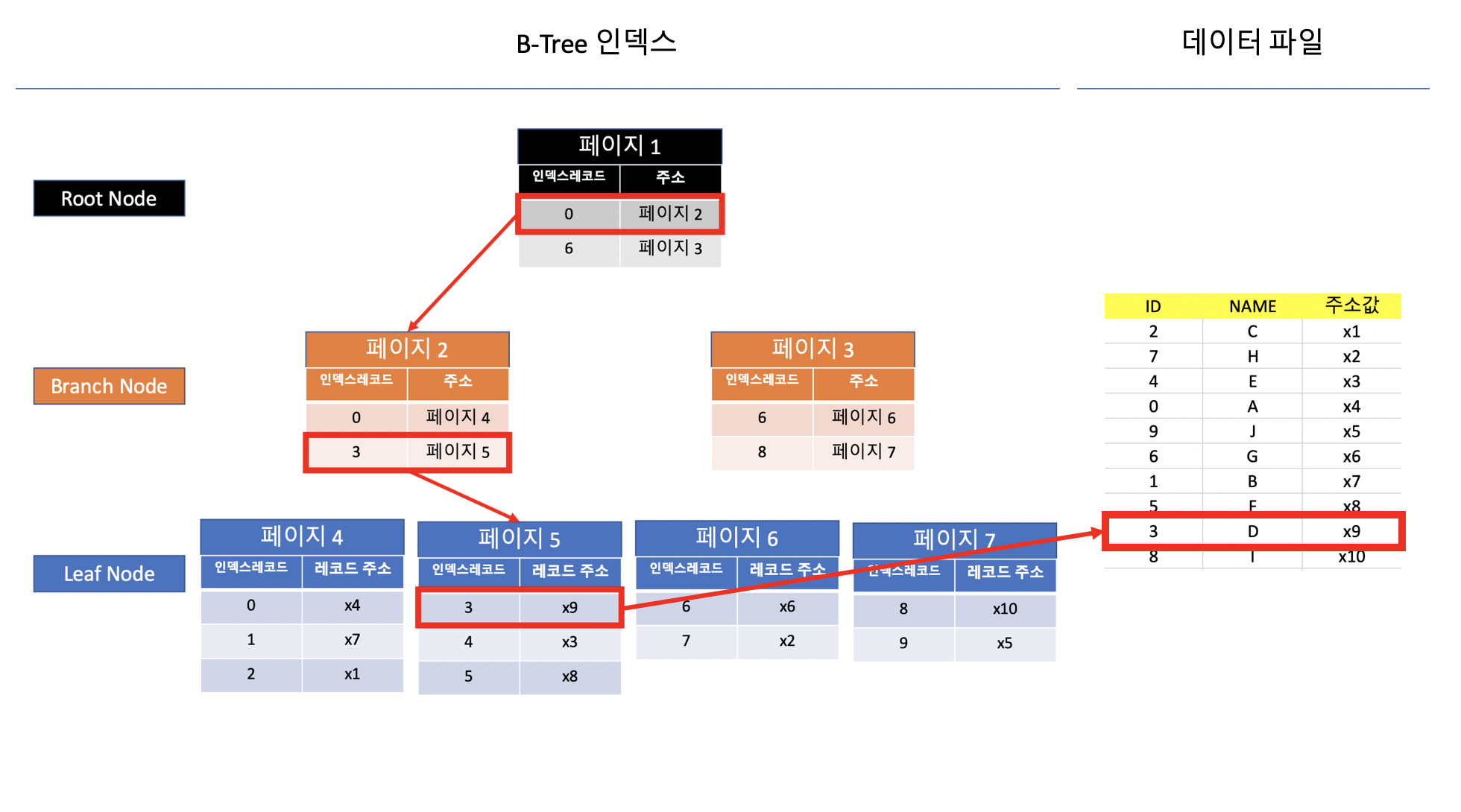
위에서 보이는것 처럼, “ID=3”에 대한 정보를 찾는다면, 총 3번의 동작으로 데이터를 찾을 수 있다.
데이터베이스에는 인덱스와 실제데이터가 따로 분류되어 저장된다.
- 3을 찾는다고 가정할때, Root Node로 접근하여 인덱스 레코드를 확인
- 인덱스 레코드를 확인하였을 때, 0부터 5까지는 페이지2에 저장되어 있는것을 확인
- 이제 Branch Node로 내려가서, 페이지 2로 접근
- 페이지 2에서, 3부터 5까지는 페이지 5에 저장되어 있는것을 확인
- 이제 Leaf Node로 내려가서 페이지 5로 접근
- Leaf Node에는 다음 페이지로 향하는 길이 없으며, 디스크에 저장되어 있는 주소를 찾아갈 수 있는 주소가 있음
- Leaf Node에서 “3”을 찾고 레코드 주소 x9을 활용하여 디스크에 있는 데이터 (ID 3, Name D)를 찾아냄
댓글남기기