
[ELK] elastic search의 Cluster 구성
Node
elasticsearch의 node에는 역할에 따라 아래와 같이 여러 가지 종류가 있다.
Master-eligible node
The master node is responsible for lightweight cluster-wide actions such as creating or deleting an index, tracking which nodes are part of the cluster, and deciding which shards to allocate to which nodes. It is important for cluster health to have a stable master node.
Data node
Data nodes hold the shards that contain the documents you have indexed. Data nodes handle data related operations like CRUD, search, and aggregations. These operations are I/O-, memory-, and CPU-intensive. It is important to monitor these resources and to add more data nodes if they are overloaded.
Ingest node
Ingest nodes can execute pre-processing pipelines, composed of one or more ingest processors. Depending on the type of operations performed by the ingest processors and the required resources, it may make sense to have dedicated ingest nodes, that will only perform this specific task.
Machine learning node
*The machine learning features provide machine learning nodes, which run jobs and handle machine learning API requests.
Coordinate node*
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place(s).
출처 : elasticsearch 공식 document - https://www.elastic.co/guide/en/elasticsearch/reference/7.5/modules-node.html
Master-eligible node
master로 선출될 수 있는 node. 말 그대로 matser node가 될 수 있는 node이다.
마스터 노드는 index를 생성 또는 삭제하거나 shard를 할당하는 등 전체적으로 index나 node들을 관리하는 역할을 하는 매우 중요한 node이다. cluster 구성 없이 1개 node로 elasticsearch를 사용할 경우엔 해당 node가 matser 역할과 data를 저장하는 역할을 모두 수행하지만, 여러 node로 cluster를 구성할 경우에는 master 역할만 하는 node와 data를 저장하기만 하는 node로 구분해서 사용하는게 일반적이다. 따라서 master node에는 데이터가 저장되지 않는다. 순전히 index 관리와 node 및 cluster 관리에만 집중하는 node라 보면 된다.
여기서 중요한 부분은 master node가 아니라 master-eligible node라는 것이다. 맨처음 말했듯 master로 선출 가능한 node다. 여러 개 node로 cluster를 구성할 때 master node의 역할은 위에 언급했듯 상당히 중요하다. 따라서 master node가 의도치 않게 죽게 될 경우 cluster에 치명적인 영향을 미칠 것이다. 그래서 master node가 죽을 경우를 대비해 master node 후보들을 지정해두게 된다. master node가 죽을 경우 다른 후보가 master node가 되어 그 기능을 수행하도록 하는 것이다.
Data node
data node는 간단하게 말하면 데이터를 저장하는 역할을 한다.
흔히 CRUD(Create, Read, Update, Delete)라고 하는 데이터 관련된 행위를 수행하는 node이다. coordinate node가 없을 경우에는 aggregation 쿼리(SQL에서 사용하는 집계와 비슷한 의미)도 수행한다.
Ingest node
ingest node는 preprocessing 과정을 수행하는 노드이다.
elastic search는 logstash나 beats 혹은 REST API 등을 통해 데이터를 받은 뒤 데이터를 저장하기 전에 전처리를 통해 원하는 방식으로 데이터를 변형해 저장할 수 있다. 이러한 전처리 과정만을 전문적으로 수행하는 node가 ingest node이다. 전처리하는 데이터가 많다면 ingest node를 추가하는게 성능 향상에 도움이 된다고 한다.
Machine learing node
머신러닝 전담 node이다. 머신러닝 기능을 사용할 경우 별도의 머신러닝 node를 필수로 생성해야 한다.
Coordinate node
중요한 node다. 사용자의 요청에 대한 일종의 로드 발란서 역할을 하는 node이다.
일반적으로 data node는 상시 혹은 주기적으로 데이터를 indexing 하고 있을 것이다. 그런데 사용자에 의해 aggregation 쿼리를 수행하게 될 경우 data node는 aggregation을 수행하느라 상당한 자원을 소모하게 된다. aggregation은 많은 메모리를 필요로 하기 때문에 정작 본인의 기본적인 role인 데이터 indexing 보다 aggregation에 더 많은 자원을 소모하게 되어 제 기능을 제대로 수행하지 못하게 될 수 있다.
coordinate node는 이러한 aggregation 쿼리를 받아 각 data node에 적절하게 요청을 분산하고 이를 취합해 aggregation을 수행하는 역할을 한다. data node에는 단순한 search 쿼리만 날리게 되어 data node의 부하를 줄여줌으로써 본래의 indexing 기능을 충실히 수행할 수 있도록 해준다.
Cluster
이러한 node들을 여러개 묶어서 하나의 elasticsearch 서비스를 제공하는 묶음이 cluster이다.
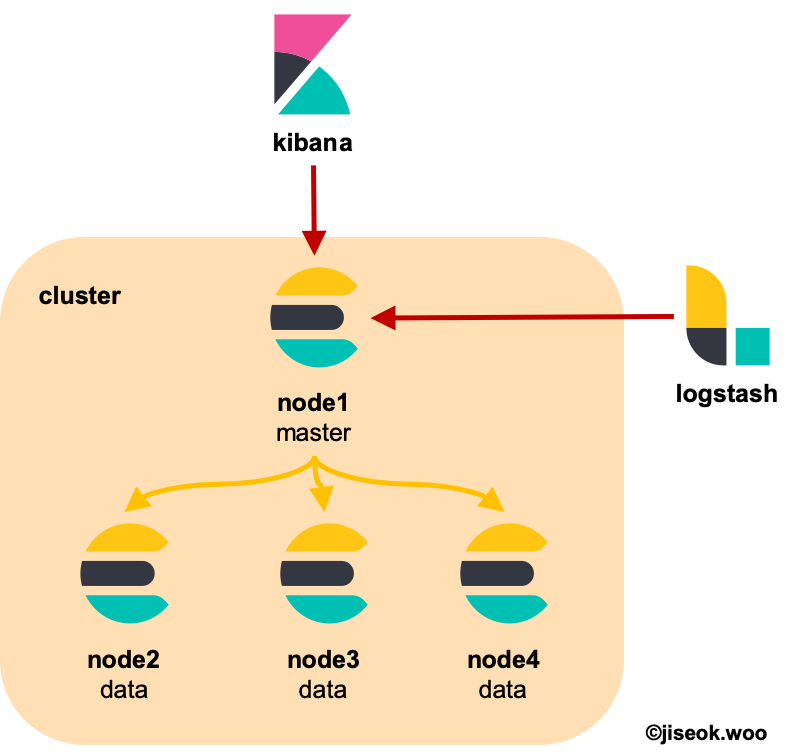
출처 : https://jiseok-woo.tistory.com/
댓글남기기