
아파치 스톰(Apache Storm) 개념
스톰(Apache Storm)
스톰(Storm)은 스피드 데이터를 인메모리 상에서 병렬 처리하기 위한 소프트웨어다. 빅데이터 V3중 속도에 해당하는 스피드 데이터는 원천 시스템의 수많은 이벤트(클릭/터치, 위치, IoT 등)가 만들어 내며, 작지만 대규모의 동시다발적이라는 특성이 있다. 이 스피드 데이터를 실시간으로 분석할 수 있다면 원천에서 무슨 일이 발생하고 있는지 빠르게 알아낼 수 있어 마케팅과 리스크 등의 분야에서 활용 가치가 높다. 스톰은 이러한 스피드 데이터를 실시간으로 다루기 위해 모든 데이터를 인메모리 상에서 분산 병렬 처리하고, 분산 데이터를 통제하기 위한 강력한 기능(분리, 경제, 통합, 집계 등)과 아키텍처도 제공한다.
실시간 분산 처리 유형으로는 데이터 발생과 동시에 처리하는 완전 실시간 방식과 발생한 데이터를 적재한 후 빠르게 배치를 실행하는 마이크로 배치 방식이 있다. 스톰은 전자에 해당하는 완전 실시간 방식으로, 조금의 레이턴시도 허용되지 않는 아키텍처에 적용한다.
구성 요소
| Spout | 외부로부터 데이터를 유입받아 가공 처리해서 튜플을 생성, 이후 해당 튜플을 Bolt에 전송 |
|---|---|
| Bolt | 튜플을 받아 실제 분산 작업을 수행하며, 필터링, 집계, 조인 등의 연산을 병렬로 실행 |
| Topology | Spout-Bolt의 데이터 처리 흐름을 정의, 하나의 Spout와 다수의 Bolt로 구성 |
| Nimbus | Topology를 Supervisor에 배포하고 작업을 할당, Supervisor를 모니터링하다 필요 시 Fail-Over 처리 |
| Supervisor | Topology를 실행할 Worker를 구동시키며 Topology를 Worker에 할당 및 관리 |
| Worker | Supervisor 상에서 실행 중인 자바 프로세스로 Spout와 Bolt를 실행 |
| Executor | Worker 내에서 실행되는 자바 스레드 |
| Tasker | Spout 및 Bolt 객체가 할당 |
스톰 아키텍처

-
Nimbus가 자바 프로그램으로 구성된 Topology Jar를 배포하기 위해 주키퍼로부터 Supervisor 정보를 알아낸다.
-
Topology Jar 파일을 각 Supervisor에 전송한다.
-
Supervisor는 해당 Node에서 Worker, Executor를 만들고, Sout과 Bolt가 실행되기 위한 Task를 할당한다.
-
Supervisor가 정상 배포되면,
External Source Application 1에서 발생한 데이터가 Spout를 통해 유입되기 시작한다. -
이를 다시 Bolt가 전달받아 데이터를 분산 처리하고, 처리 결과는 Bolt를 통해 타깃 시스템인
External Target Application 2로 전송된다.이때 Task, Executor 개수를 증가시키면서 대규모 병렬 처리가 가능해지고 Spout와 Bolt의 성능이 향상된다.
스톰의 아키텍처는 견고한 장애 복구 기능을 제공한다.
특정 Supervisor가 생성한 Worker프로세스가 종료되면 Supervisor는 새로운 Worker 프로세스를 다시 생성. 처리 중이던 데이터들은 이전 수신지로 롤백. Topology가 정상 복구되면 롤백 시점부터 다시 처리.
| 장점 | 단점 |
|---|---|
| - 실시간 처리에 적합 - 마이크로 배치 처리도 지원함 - 스트림 처리의 스타일을 사용자가 지정할 수 있음 - 다양한 언어 지원 |
- 실행중인 토폴로지를 업데이트 하려면 현재 토폴로지를 종료하고 다시 제출해야 함 |
Storm vs Spark Streaming
1. Task Prallel vs. Data Parallel
계산 프로그래밍 모델에서부터 느낄 수 있는 가장 뚜렷한 차이는 먼저, Storm은 Task Parallelism이고 Spark Streaming은 Data Parallelism이다. Storm의 계산 그래프 구조를 통해 보다 완성도 높은 시스템을 구현할 수 있지만 코드의 복잡도 면에서는 Spark가 유리할 수 있다.
2. Streaming vs. Micro-batches
Spark streaming의 경우는 엄밀히 말하면 실시간 처리보다는 작은 단위의 배치 연속이라고 할 수 있다. Storm은 전형적인 event-driven record at a time processing model로써 살아있는 데이터를 처리한다고 하면, Spark은 휴면 상태로 넘어간 데이터를 처리한다. 때문에 Latency에서 차이가 발생하는데 Storm은 subsecond, Spark의 경우에는 사용자 임의지정 few seconds가 된다.
여기에서 중대한 차이점이 발생하는데, Storm의 경우에는 데이터 유실이 없어야 할 때 (no data loss), Spark은 중복 연산이 없어야할 때 (exactly once) 선택하는 것이 좋다.
한편, Storm Trident는 Micro-batches 스타일도 가능하다고 한다.
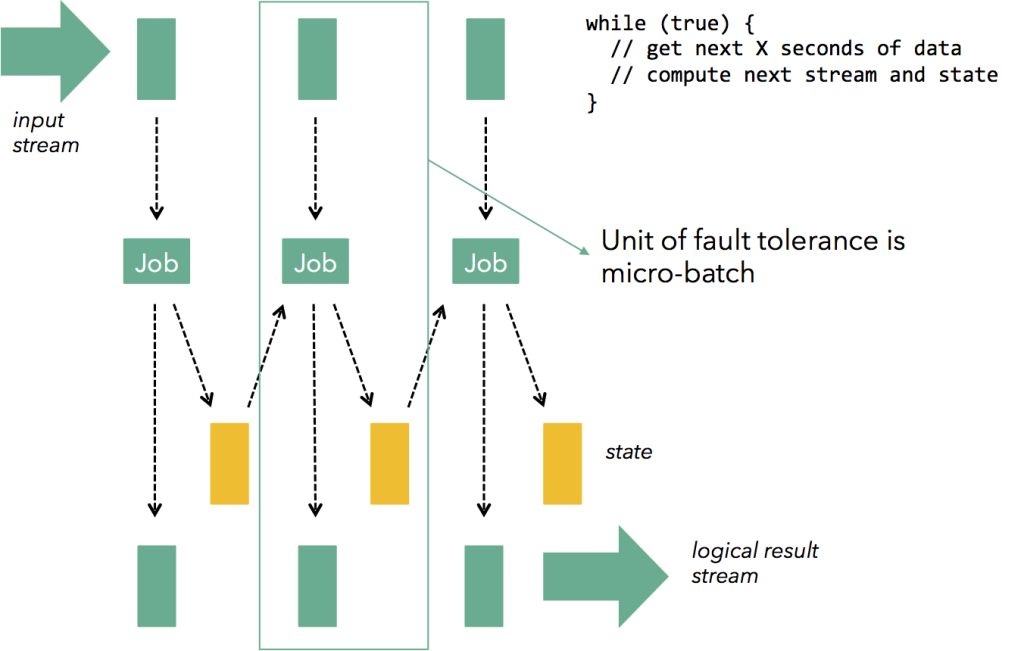
3. Stateless vs. Stateful
앞서 소개한대로 Storm은 매 레코드 별로 처리하기 때문에 State을 유지하지 않기 때문에 장애 복구 메커니즘이 Spark보다 복잡하고 re-launching 시간이 더 걸릴 것이다. Stateless vs. Stateful는 (뭔가 더 있을 것 같지만) 장애 복구 외의 차이점은 전혀 없다.
댓글남기기