
[Spark] spark 데이터 구조 비교
Spark 데이터 구조
- RDD
- DataFrame(Spark 1.X version)
- DataSet(Spark 2.X version)
RDD
우선 Spark의 기본 데이터 타입인 RDD부터 살펴보기로 하자. RDD는 Resilient Distributed Datasets 의 약자로 다음과 같이 설명하고 있다. (http://www-bcf.usc.edu/~minlanyu/teach/csci599-fall12/papers/nsdi_spark.pdf)
RDD - Fault- Tolerant를 보장하기 위해 클러스터내에서 인메모리 연산이 가능하도록 하는 탄력적인 분산 데이터 셋이다.
다음 예제에서 HDFS에 저장된 로그로 부터 ERROR를 추출한후 HDFS를 추출하여 time field를 추출하는 예제이다.
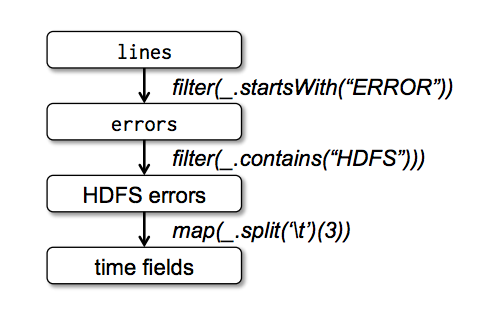
Lineage graph for the third query in our example. Boxes represent RDDs and arrows represent transformations.
각각의 box는 RDD를 뜻하며 filter,map등의 coarse-grained transformations를 수행하였다.
코드로 표현하면 다음과 같다.
lines = spark.textFile("hdfs://...") //HDFS path로 부터 로그 파일을 읽어 lines란 RDD를 생성한다.
errors = lines.filter(_.startWith("ERROR")) //lines RDD로 부터 ERROR시작되는 데이터만 필터링 하여 errors RDD를 생성한다.
errors.persist() //in memory에 errors RDD를 persist한다.
errors.count() //errors의 count를 세려고 action을 수행한다. spark은 lazy execution 방식으로 동작한다.
errors.filter(_.contains("HDFS")) //errors RDD에서 HDFS문자열이 포함되어 있는 경우 tab으로 분리하여 3번째 필드를 가져오려고 한다.
.map(_.split('\t')(3)) //여기서는 3번째 field가 time이라고 가정한다.
.collect() //time field에 대한 결과 값을 리턴한다.
위의 그림처럼 각 RDD는 연결되어 있으며 해당 box가 실패하는 경우 이전 단계로 re-processing을 수행하는 lineage graph를 갖고 있다. In-memory computing에서의 Fault Tolerance를 보장하기 위함이다.
RDD를 사용하는 3가지 상황
-
높은 레벨의 API에서 찾을 수없는 어떠한 기능이 필요할 때 사용
( ex) 클러스터를 통해 물리적 데이터선정을 빡빡하게 제어해야될 때)
-
RDD를 기반으로 짠 기존 코드를 유지해야 할 때
-
shared variable 조작을 설정해야될 때.
RDD 특징
- Java, Scala의 객체를 처리하는 방식
- 함수를 1) Transformation 2) Action으로 나눠 Action에 해당하는 함수를 호출할 때 실행된다.
- transformation의 결과는 RDD로 생성
- 내부에 데이터 타입이 명시
- 쿼리 최적화등을 지원하지 않았음(카탈리스트 옵티마이저 X)
- Pyspark에서 UDF선언시 인터프리터와 JVM사이 커뮤니케이션으로 속도가 저하됨( Python의 경우 Scala의 2배), 반드시 built in 함수만 쓸 것
- 병렬적으로 처리한다
- immutable(수정할 수 없다)
- lineage를 통한 fault tolerent를 보장함으로써 속도가 빠르다.
- Transformation: RDD에서 새로운 RDD를 생성하는 함수, 스파크의 동작중에서 데이터를 처리하는 명령 ex) map, filter, flatMap, join
- Action: RDD에서 RDD가 아닌 타입의 data로 변환하는 함수, Transformation의 결과를 저장하는 명령 ex) count, collect, reduce, save
DataFrame
Spark 1.3.X부터 릴리즈된 DataFrame은 named column으로 구성된 데이터의 분산 집합이다. named column에서 의미하듯이 스키마를 가진 RDD이다. R/Python에서의 data frame/pandas모듈과 유사하고 Spark내부에서 최적화 할 수 있도록 하는 기능들이 추가되었다.
또한, 기존 RDD에 스키마를 부여하고 질의나 API통해 데이터를 쉽게 처리 할 수 있다. 대규모의 데이터 셋을 더욱 쉽게 처리 할 수 있도록 High-level API 를 지원하여 RDD programming 보다 더 직관적으로 구현이 가능하도록 추상적인 인터페이스를 지원한다.
Spark2.0에서는 DataFrame과 Datasets가 Datasets으로 병합되어 데이터 처리를 통합하고 있다.
내부적인 동작 방식에는 Catalyst Optimizer를 통해 실행 시점에 최적화된 코드를 제공하고 있어 RDD 프로그래밍과 달리 언어(Scala, Java, Pytho, R)에 상관없이 동일한 성능을 보장한다.
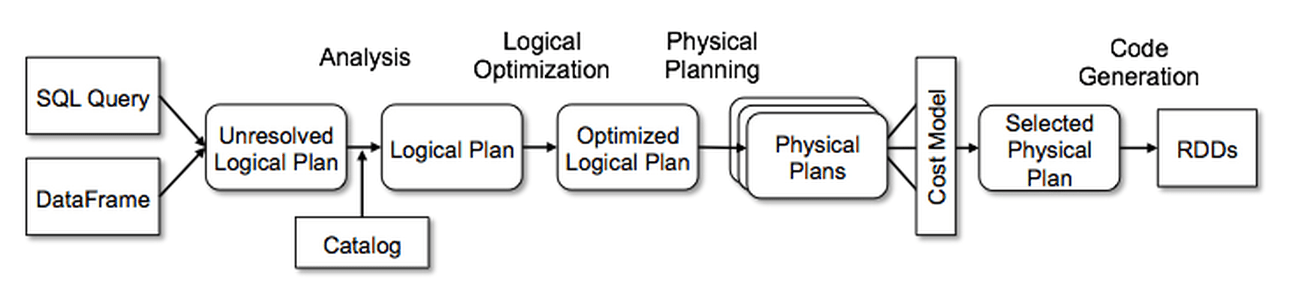
- SparkSession을 통해 만들어지는 데이터 타입
- spark = SparkSession.builder.appName(“이름”).master(“local[*]”).getOrCreate()
df = spark.read.format(“형식”).option(“옵션”,”true”).load(“주소.파일형식”)
//df는 dataframe타입으로 만들어지게 된다.
- 대부분의 경우에 dataframe을 사용(테이블 생성을 통한 SQL질의도 가능하기 때문)
dataframe 특징
- 내부 데이터가 Row라는것만 명시, 실제 데이터 타입은 알 수 없음
- 스키마 추상화
- Python Wrapper코드로 Python에서의 성능이 향상되었다.
- Dataset 제네릭 객체 집합에 대한 별칭
- RDD와 마찬가지로 Pyspark에서 함수를 선언해서 사용할 경우(UDF), 속도 저하의 원인이 될 수 있다.
- 카탈리스트 옵티마이저 지원
- SparkSQL을 통해 사용할 수 있다(RDBMS에 익숙한 사람들의 경우 편리함)
- RDB처럼 테이블을 가질 수 있으며, 테이블에 대한 연산이 가능하다.
- Named Column으로 구성
- immutable(수정될 수 없다.)
Datasets
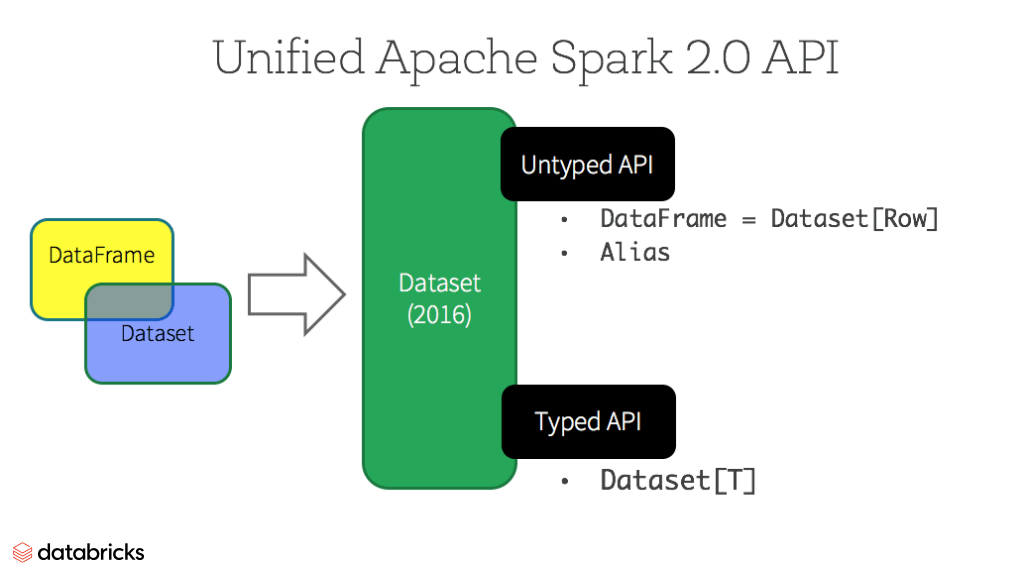
Spark2.0부터는 Dataset은 강력한 형식의 API와 형식이 지정되지 않는 API두가지를 사용한다. 개념적으로 DataFrame은 Dataset[Row]로 간주되며 Dataset의 subset으로 볼 수 있다. 여기서 Row는 유형이 지정되지 않는 JVM객체이다. Dataset은 Scala 나 Java클래스에서 정의하는 case class를 통해 타입을 선언한 강력한 형식의 JVM객체의 모음이다. Datasets은 Scala와 Java만 지원하는데 Python과 R의 경우 컴파일 타임형 안정성이 없기 때문이다.
dataset 특징
- 데이터타입이 명시되어야함
- 스키마 추상화
- Scala/Java에서 정의한 클래스에 의해 타입을 명시해야하는 JVM객체. 따라서 Python은 지원하지 않음.
- 카탈리스트 옵티마이저 지원
- Type-safe
- RDD와 Dataframe의 장점을 취한다.
Datasets의 이점
정적 타이핑 및 런타임 유형 안전
아래 도식에서 보듯이 SQL은 데이터 집합에 대해 구문에러 분석 에러에 대해 제한적이다. 즉 Spark SQL문자열 쿼리에서 런타임까지 구문 오류를 알 수 없다. 반면에 Dataframe과 Dataset의 경우 컴파일 타임에 오류를 잡을 수 있다. Dataframe에서 API의 일부가 아닌 함수를 호출하면 컴파일 시점에 에러가 나지만 런타임에서는 존재 하지 않는 열 이름을 감지 할 수 없다. Dataset의 경우 람다 함수 및 JVM유형 객체로 표현되기 때문에 유형이 지정된 매개변수의 불일치가 컴파일 시점에 감지되며 분석오류까지 알 수 있다. Dataset의 경우 개발자에게는 제약이 많이 따르지만 생산적인 측면도 있다.
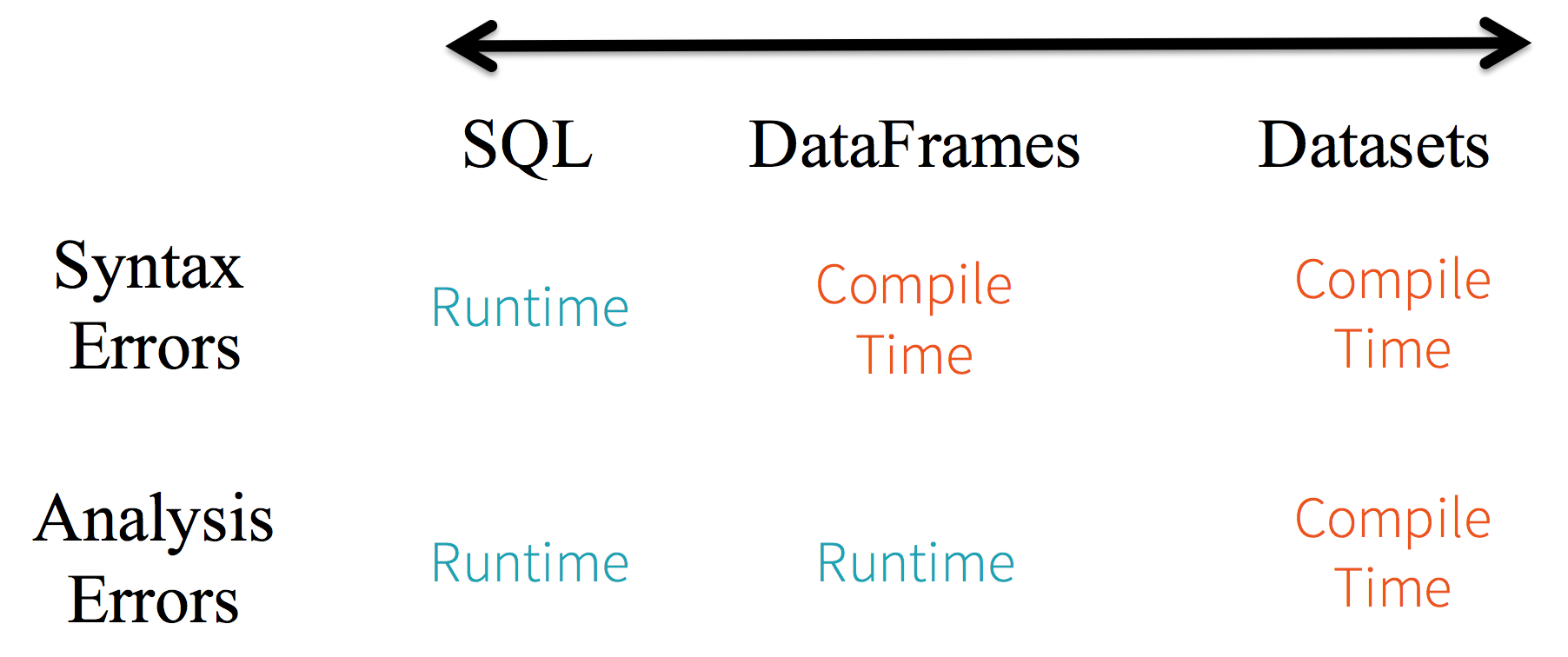
sql vs dataframe vs dataset
사용 편의성
Dataset은 높은 수준의 API로 수행할 수 있어서 Dataset의 유형 객체에 대해 직접 엑세스 하여 agg, select, sum, avg, map, filter, groupBy등의 작업을 수행하는 것이 더욱 간결해 졌다.
// Use filter(), map(), groupBy() country, and compute avg()
// for temperatures and humidity. This operation results in
// another immutable Dataset. The query is simpler to read,
// and expressive
val dsAvgTmp = ds.filter(d => {d.temp > 25}).map(d => (d.temp, d.humidity, d.cca3)).groupBy($"_3").avg()
//display the resulting dataset
display(dsAvgTmp)
성능 및 최적화
댓글남기기