
[Spark] RDD란?
RDD 개념
스파크의 데이터 처리는 RDD를 이용한다. 스파크의 프로그래밍 모델은 RDD를 가공해 새로운 RDD를 만들고, 이런 처리를 반복하여 원하는 결과를 얻는 형태다. RDD(Resilient Distributed Dataset)를 해석하면 분산되어 존재하는 데이터들의 모임(데이터셋)이다. 내부는 파티션이라는 단위로 나뉘며, 이 파티션이 분산처리 단위다. RDD를 파티션 단위로 여러 머신에서 처리하므로 한 대의 머신으로 처리할 수 있는 것보다 더 큰 데이터를 다룰 수 있다.
- Resillient(회복력 있는, 변하지 않는) : 메모리 내부에서 데이터가 손실 시 유실된 파티션을 재연산해 복구할 수 있음 - Distributed(분산된) : 스파크 클러스터를 통하여, 메모리에 분산되어 저장됨
RDD는 Resillient 즉, 불변의 특성을 가지는데(Read Only), 그렇기 때문에 특정 동작을 위해서는 기존 RDD를 변형한 새로운 RDD가 생성될 수밖에 없다. 그래서 위처럼 Spark 내의 연산에 있어 수많은 RDD들이 생성되게 되는 것이다.
특정 동작에 의해 생성되는 RDD Lineage는 아래와 같은 DAG(Directed Acyclic Graph)의 형태를 가진다.
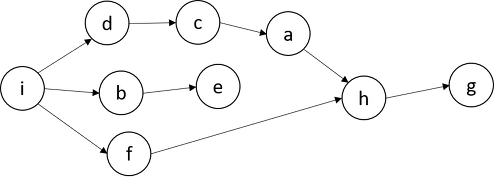
노드간의 순환(cycle : 시작점과 끝점이 같은 형태)이 없으며, 일정항 방향성을 가지기 때문에 각 노드 간에는 의존성이 있으며, 노드 간의 순서가 중요한 형태이다.
이러한 DAG에 의하여, 특정 RDD 관련 정보가 메모리에서 유실되었을 경우, 그래프를 복기하여 다시 계산하고, 자동으로 복구할 수 있다. 스파크는 이러한 특성 때문에 Fault-tolerant(작업 중 장애나 고장이 발생하여도 예비 부품이나 절차가 즉시 그 역할을 대체 수행함으로써 서비스의 중단이 없게 하는 특성)를 보장하는 강력한 기능을 가지고 있다.
RDD 동작 원리
RDD는 스파크의 가장 기본적인 데이터 단위이다. 모든 작업은 새로운 RDD를 생성하거나/이미 존재하는 RDD를 새로운 RDD로 변형하거나/최종 결과 계산을 위해 RDD에서 연산 API를 호출하는 것 중 하나에 의해 수행된다. (Read Only 특성 때문)
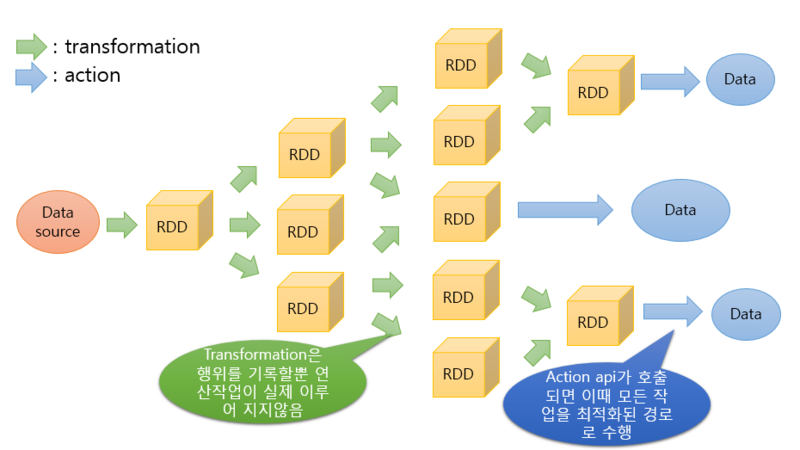
이처럼 특정 Data source로부터 최종 Data에 도달하기 위해서는, 많은 RDD가 새로 생성되고 변형되는 작업이 발생한다.
RDD 동작 원리의 핵심은 Lazy Evaluation(지연실행)이라는 키워드에 있다. Lazy Evaluation이란, 쉽게 말해 즉시 실행하지 않는 것을 의미한다. Action 연산자를 만나기 전까지는, Transformation 연산자가 아무리 쌓여도 처리하지 않는다. 이는 Hadoop의 Map Reduce 동작과 대조적이기 때문에, Spark는 간단한 operation들에 대한 성능적 이슈를 고려하지 않아도 된다는 장점을 가지고 있다.
Lazy Evalution
Spark Cluster의 Driver Program에서는 Job(RDD의 변환 및 액션으로 구성된 실행 단위)을 선언만 할 뿐, 실제 실행은 Cluster Manager에 의해 할당된 각각의 Worker Node의 Executor에 의해 실행된다. (자세히 말하면, Driver Program에 의해 job이 task로 쪼개지고, executor는 할당된 task를 실행)
이것이 RDD가 한 대의 머신에서 전부 다룰 수 없을 만큼 크고 많은 데이터를 (논리적으로)가질 수 있는 이유이다.
Transformation & Action
RDD는 Transformation과 Action으로 동작한다.
Transformation(변환) 연산자는 기존 RDD에서 새로운 RDD를 생성하는 동작이며, 변환에 따른 RDD를 return 한다. Transformation에서는 Spark가 실제 연산작업을 수행하지는 않는다.
| 이름 | 용도 |
|---|---|
| map() | RDD의 각 요소에 함수를 적용하고, 결과 RDD를 리턴한다. (ex. rdd.map(x : x+2) : 각 요소에 2씩 더함) |
| filter() | 조건에 통과한 값만 리턴한다. |
| distinct() | RDD의 값 중 중복을 제거한다. |
| union() | 두 RDD에 있는 데이터를 합친다. (RDD간 합집합) |
| intersection() | 두 RDD에 모두 있는 데이터만을 반환한다. (RDD간 교집합) |
Action 연산자는 기록된 모든 작업을 실제 수행하는 연산자이며, 데이터 또는 실행결과를 리턴한다.
| 이름 | 용도 |
|---|---|
| collect() | RDD의 모든 데이터를 리턴한다. |
| count() | RDD의 값 갯수를 리턴한다. |
| top(num) | 상위 num 갯수만큼 리턴한다. |
| takeOrdered(num)(Ordering) | Ordering 기준으로 num 갯수만큼 리턴한다. |
| reduce(func) | RDD의 값들을 병렬로 병합 연산한다. (병합 기준 : func) |
출처
- https://artist-developer.tistory.com/17?category=962892
- 책, 스파크를 다루는 기술(spark in action)
댓글남기기