
[Spark] 스파크의 실행 구조
스파크의 실행구조
스파크는 병렬 분산 환경을 사용자가 의식하지 않아도 병렬 분산 환경에서의 처리가 진행된다. 스파크에는 데에터셋을 추상적으로 다루기 위한 RDD라는 데이터셋이 있으며, RDD가 제공하는 API로 변환을 기술하기만 하면 처리되게끔 구현되었다.
스파크는 크게 스파크 어플리케이션과 클러스터 매니저로 구성되어 있다.
Spark Application
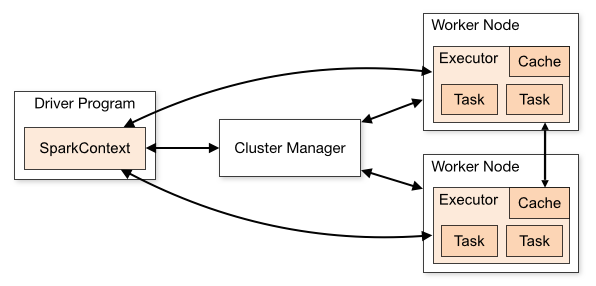
스파크 어플리케이션은 실제 일을 수행하는 역할을 담당하며, Driver 프로세스와 익스큐터 프로세스로 구성된다.
Spark Driver는 한 개의 노드에서 실행되며, 스파크 전체의 main() 함수를 실행한다. 어플리케이션 내 정보의 유지 관리, 익스큐터의 실행 및 실행 분석, 배포 등의 역할을 수행한다. 사용자가 구성한 사용자 프로그램(Job)을 task 단위로 변환하여, Executor로 전달한다.
Executer는 다수의 worker 노드에서 실행되는 프로세스로, Spark Driver가 할당한 작업(task)을 수행하여 결과를 반환한다. 또한 블록매니저를 통해 cache하는 RDD를 저장한다.
Executor는 Cluster Manager에 의해 해당 스파크 어플리케이션에 할당되며, 해당 스파크 어플리케이션이 완전히 종료된 후 할당에서 해방된다. 그렇기 때문에, 서로 다른 스파크 어플리케이션 간의 직접적인 데이터 공유는 불가능하다. (각 스파크 어플리케이션이 별도의 JVM프로세스에서 동작하므로)
Cluster Manager
스파크 어플리케이션의 리소스를 효율적으로 분배하는 역할을 담당한다. 스파크는 익스큐터를에 태스크를 할당하고 관리하기 위하여 클러스터 매니저에 의존한다.
클러스터 매니저 종류
Yarn, Mesos, Kubernetes 등
Spark StandAlone - 클러스터가 아닌 단일 서버에서 스파크 전체를 동작시키는 방식
Worker 노드에 여러개의 Executor를 실행시킬 수 있는 Yarn, Mesos, K8s와 달리, StandAlnoe 모드의 경우 Executor는 Worker 노드 하나당 한개 씩 동작한다.
Spark Application 실행 과정
사용자가 Spark를 사용할 때의 대략적인 실행 흐름은 다음과 같다.
- 사용자가 Spark-submit을 통해 어플리케이션을 제출한다.
- Spark Driver가 main()을 실행하며, SparkContext를 생성한다.
- SparkContext가 Cluster Manager와 연결된다.
- Spark Driver가 Cluster Manager로부터 Executor 실행을 위한 리소스를 요청한다.
- Spark Context는 작업 내용을 task 단위로 분할하여 Excutor에 보낸다.
- 각 Executor는 작업을 수행하고, 결과를 저장한다.
- 드라이버의 main()이 끝나거나 SparkContext.stop()이 호출된다면 Excutor들은 중지되고 클러스터 매니저에 사용했던 자원을 반환한다.
출처
-https://artist-developer.tistory.com/8?category=962892
-책, 스파크를 다루는 기술(spark in action)
댓글남기기